
[표식찾기 연습]
1단계 코드베이스 선택
owasp-java-html-sanitizer 에서 HtmlSanitizer 클래스의 sanitize 메서드
public static void sanitize(
@Nullable String html, final Policy policy,
HtmlStreamEventProcessor preprocessor) {
String htmlContent = html != null ? html : "";
HtmlStreamEventReceiver receiver = initializePolicy(policy, preprocessor);
receiver.openDocument();
HtmlLexer lexer = new HtmlLexer(htmlContent);
// Use a linked list so that policies can use Iterator.remove() in an O(1)
// way.
LinkedList<String> attrs = Lists.newLinkedList();
while (lexer.hasNext()) {
HtmlToken token = lexer.next();
switch (token.type) {
case TEXT:
receiver.text(
Encoding.decodeHtml(htmlContent.substring(token.start, token.end)));
break;
case UNESCAPED:
receiver.text(Encoding.stripBannedCodeunits(
htmlContent.substring(token.start, token.end)));
break;
case TAGBEGIN:
if (htmlContent.charAt(token.start + 1) == '/') { // A close tag.
receiver.closeTag(HtmlLexer.canonicalElementName(
htmlContent.substring(token.start + 2, token.end)));
while (lexer.hasNext()
&& lexer.next().type != HtmlTokenType.TAGEND) {
// skip tokens until we see a ">"
}
} else {
attrs.clear();
boolean attrsReadyForName = true;
tagBody:
while (lexer.hasNext()) {
HtmlToken tagBodyToken = lexer.next();
switch (tagBodyToken.type) {
...
2단계 코드 파악: 선택한 메서드나 함수를 파악하고 코드가 하는 일을 요약
먼저 sanitize 메서드에 필요한 3개 파라미터부터 살펴보자.
@Nullable String html,
final Policy policy,
HtmlStreamEventProcessor preprocessor
1. sanitize 대상이 되는 html 문자열
2. sanitize 정책
3. HtmlStreamEventProcessor 는 네이밍으로 'html 문자열 스트림 이벤트를 처리하는 프로세스' 를 담당하는것으로 유추해볼 수 있다. 하지만 이것만으로는 정확히 무슨일을 하는지 알기 어렵다.
다음 코드를 보자.
String htmlContent = html != null ? html : "";
HtmlStreamEventReceiver receiver = initializePolicy(policy, preprocessor);
receiver.openDocument();
htmlContent 로 전달은 방어로직으로 이해했다. 다음으로 policy 와 preprocessor를 갖고 초기화 작업을 한다. 그런데 리턴 타입이 HtmlStreamEventReceiver 다. 결국 Policy, HtmlStreamEventProcessor, HtmlStreamEventReceiver 이 3개의 타입에 대해 이해가 필요하다.
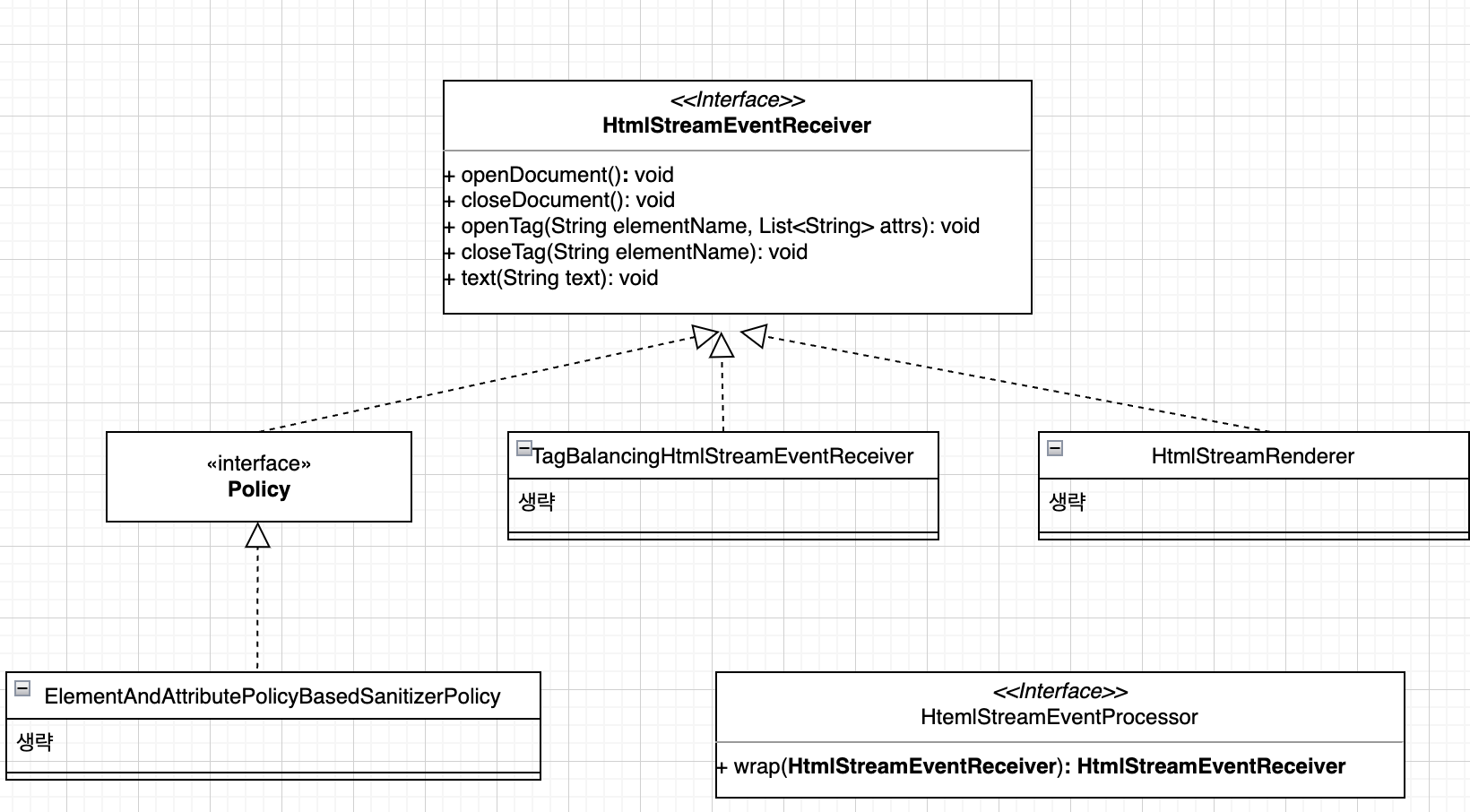
위 다이어그램을 보면 모두 HtmlStreamEventReceiver 와 연결되는것을 알 수 있다. 결론적으로 initializePolicy를 통해 얻은 receiver 변수는 TagBalancingHtmlStreamEventReceiver 타입이고 그 안에는 ElementAndAttributePolicyBasedSanitizerPolicy 를 갖고 있다. HtmlStreamEventProcessor 에서는 현재 전달받은 HtmlStreamEventReceiver 타입을 그대로 리턴하기 때문에 TagBalancingHtmlStreamEventReceiver 를 wrapping 했다고 이해하면 된다.
HtmlStreamEventReceiver receiver = initializePolicy(policy, preprocessor);
실질적인 openDocument 는 ElementAndAttributePolicyBasedSanitizerPolicy 의 openDocument 이고, 내부적으로 sanitize 결과를 담는 out(HtmlStreamRenderer 타입) 의 openDocument 가 수행된다.
receiver.openDocument();
다음 아래 코드를 보자. htmlContent 를 갖고 HtmlLexer 객체를 만든다. HtmlLexer 를 통해 htmlContent 중 의미있는 단위로 짤라서 HtmlToken 객체로 만든다(각 단위를 token이라 한다). 그리고 token type에 따라 역할들이 분기되어 있다. htmlContent를 어떻게 HtmlToken 단위로 만드는지는 내용이 방대하므로 따로 다루겠다.
HtmlLexer lexer = new HtmlLexer(htmlContent);
// Use a linked list so that policies can use Iterator.remove() in an O(1)
// way.
LinkedList<String> attrs = Lists.newLinkedList();
while (lexer.hasNext()) {
HtmlToken token = lexer.next();
switch (token.type) {
case TEXT:
...
case UNESCAPED:
...
case TAGBEGIN:
if (htmlContent.charAt(token.start + 1) == '/') { // A close tag.
...
} else {
...
}
}
}
각 token type 마다 최종적으로는 receiver.text, receiver.closeTag, receiver.openTag 에 담는다. 이중에서 가장 핵심인 코드는 TAGBEGIN인데 이것도 내용이 길어서 중간을 짤랐다. 이후 부분은 다음 분석때 다루겠다.
switch (token.type) {
case TEXT:
receiver.text(
Encoding.decodeHtml(htmlContent.substring(token.start, token.end)));
break;
case UNESCAPED:
receiver.text(Encoding.stripBannedCodeunits(
htmlContent.substring(token.start, token.end)));
break;
case TAGBEGIN:
if (htmlContent.charAt(token.start + 1) == '/') { // A close tag.
receiver.closeTag(HtmlLexer.canonicalElementName(
htmlContent.substring(token.start + 2, token.end)));
while (lexer.hasNext()
&& lexer.next().type != HtmlTokenType.TAGEND) {
// skip tokens until we see a ">"
}
} else {
attrs.clear();
boolean attrsReadyForName = true;
tagBody:
while (lexer.hasNext()) {
HtmlToken tagBodyToken = lexer.next();
switch (tagBodyToken.type) {
...
3단계 사용하는 표식의 적극적 확인
설명 : 읽는 도중 '아, 그렇구나'라는 생각이 들면서 그 코드의 의미를 좀 더 이해하게 되면 잠시 멈추고 왜 그렇게 생각했는지를 적어보라. 주석문, 변수명, 메서드명, 임시 저장값 등 어느 것이든 표식이 될 수 있다.
1. initializePolicy 작업을 통해 receiver 변수에 모든것이 계층적으로 셋팅되는것을 이해했다. 위 밴다이어그램을 통해 알 수 있듯이 HtmlStreamEventReceiver 타입으로 엮여있다.

2. Lexer 는 laxical analysis(어휘분석)을 하는 역할이다. 즉 HtmlLexer 는 html 문자열을 분석해서 token 단위로 분리시켜 sanitize 함을 알 수 있다.
3. attrs 변수는 컨테이너 객체로 linked list를 선택했는데, Iterator.remove() 를 O(1) 복잡도로 실행시키기 위함이라고 주석에 설명되어있다. 하지만 attrs 를 어떤 목적으로 사용하는지에 대해 아직 구체적으로 파악되지 않아 완전히 이해되지 않았다.
4단계 회고
- 어떤 표식을 찾았는가?
1. receiver
2. initializePolicy
3. HtmlLexer
4. HtmlToken
- 찾은 표식들은 코드의 요소인가, 아니면 사람의 언어로 된 정보인가?
코드의 요소다.
- 그 표식들은 무엇에 관해 알려주고 있는가?
1. receiver : wrapping 되어 있지만 결국 sanitize 된 결과를 담는 out 변수에 넣는 역할을 수행한다.
2. initializePolicy : receiver 구조를 만드는 작업을 수행한다. 계층적으로 다양한 객체들이 담겨있다.
3. HtmlLexer : htmlContent 를 의미있는 단위로 자르는 역할이다.
4. HtmlToken : HtmlLexer 가 token 단위로 잘르면 HtmlToken 자료구조로 담는다.
- 그 표식들은 코드의 도메인에 대한 지식을 나타내는가?
HtmlLexer, HtmlToken 은 도메인에 대한 지식이다.
- 그 표식들은 코드의 기능에 대한 지식을 나타내는가?
receiver, initializePolicy는 기능에 대한 지식이다.
[청킹연습]
1단계 코드 선정
public static void sanitize(
@Nullable String html, final Policy policy,
HtmlStreamEventProcessor preprocessor) {
String htmlContent = html != null ? html : "";
HtmlStreamEventReceiver receiver = initializePolicy(policy, preprocessor);
receiver.openDocument();
HtmlLexer lexer = new HtmlLexer(htmlContent);
// Use a linked list so that policies can use Iterator.remove() in an O(1)
// way.
LinkedList<String> attrs = Lists.newLinkedList();
while (lexer.hasNext()) {
HtmlToken token = lexer.next();
switch (token.type) {
case TEXT:
receiver.text(
Encoding.decodeHtml(htmlContent.substring(token.start, token.end)));
break;
case UNESCAPED:
receiver.text(Encoding.stripBannedCodeunits(
htmlContent.substring(token.start, token.end)));
break;
case TAGBEGIN:
if (htmlContent.charAt(token.start + 1) == '/') { // A close tag.
receiver.closeTag(HtmlLexer.canonicalName(
htmlContent.substring(token.start + 2, token.end)));
while (lexer.hasNext()
&& lexer.next().type != HtmlTokenType.TAGEND) {
// skip tokens until we see a ">"
}
} else {
attrs.clear();
boolean attrsReadyForName = true;
tagBody:
while (lexer.hasNext()) {
HtmlToken tagBodyToken = lexer.next();
switch (tagBodyToken.type) {
2단계 코드 파악
설명: 최대 2분을 넘지 않도록 타이머를 설정하고 코드 파악. 시간이 다 되면 코드는 보지 않는다.
3단계 코드 재현
설명: 기억을 되살려 새롭게 코드를 다시 작성
public static void sanitize(
@Nullable String html,
HtmlSanitizer.Policy policy,
HtmlStreamEventProcessor preProcessor
) {
String htmlContent = html != null ? html : "";
HtmlStreamEventReceiver receiver = initializePolicy(policy, preProcessor);
receiver.openDocument();
LinkedList<String> attrs = Lists.newLinkedList();
HtmlLexer lexer = new HtmlLexer(htmlContent);
while (lexer.hasNext()) {
HtmlToken token = lexer.next();
switch (token.type) {
case TEXT:
// token substring
receiver.text();
break;
case UNESCAPED:
// token substring
receiver.text();
break;
case TAGBEGIN:
if () { // close tag </
// token substring
} else {
while(lexer.hasNext()) {
HtmlToken tagBodyToken = lexer.next();
// receiver.openTag
}
}
break;
}
}
}
private static HtmlStreamEventReceiver initializePolicy(HtmlSanitizer.Policy policy, HtmlStreamEventProcessor preProcessor) {
TagBalancingHtmlStreamEventReceiver sink = new TagBalancingHtmlStreamEventReceiver(policy);
sink.setNestingLimit(256);
return preProcessor.wrap(sink);
}4단계 회고
- 어느 부분을 쉽게 기억했는가?
1. sanitize signature
2. initializePolicy
3. HtmlLexer 그리고 while - switch 전체 구조.
- 부분적으로 기억한 코드가 있는가?
switch case 별로 작업하는 코드들
- 전체를 다 기억하지 못한 코드가 있는가?
tagBodyToken 부분
- 기억하지 못한 라인들이 있다면 그 이유가 무엇일까?
시간부족.
- 기억하지 못한 라인에 본인이 익숙하지 않은 프로그래밍 개념이 들어 있지는 않는가?
없다.
- 기억하지 못한 라인에 본인이 익숙하지 않은 도메인 지식이 있지는 않는가?
receiver.text 나 receiver.closeTag 에 들어갈 값들에 대해 추가적인 작업이 필요한데 Encoding.decodeHtml, Encoding.stripBannedCodeunits 이 왜 필요한지에 대해 아직 도메인 지식이 부족한다.
그리고 HtmlToken 이 만들어지는 구체적인 프로세스에 대한 도메인 지식이 부족해서 htmlContent.substring 로직들을 잘 기억해내지 못했다.
'연습' 카테고리의 다른 글
| 프로그래머뇌 청킹연습/표식찾기연습 - 3 (0) | 2022.05.25 |
|---|---|
| 프로그래머뇌 청킹연습/표식찾기연습 - 1 (0) | 2022.05.11 |
| [구현] 자물쇠와 열쇠 (0) | 2021.12.06 |
| [구현] 문자열 압축 (0) | 2021.11.29 |
| [구현] 문자열 재정렬 (0) | 2021.11.21 |



